In [5]:
degree_sequence = sorted([d for n, d in G.degree(weight='weight')], reverse=True)
dmax = max(degree_sequence)
fig = plt.figure("Degree of a random graph", figsize=(8, 8))
# Create a gridspec for adding subplots of different sizes
axgrid = fig.add_gridspec(5, 4)
ax0 = fig.add_subplot(axgrid[0:3, :])
Gcc = G.subgraph(sorted(nx.connected_components(G), key=len, reverse=True)[0])
pos = nx.spring_layout(Gcc, weight='weight', seed=10396953)
nx.draw_networkx_edges(Gcc, pos, ax=ax0, alpha=0.1)
_, viewers_number = zip(*list(Gcc.nodes("viewers")))
scaled_viewers_number = list(map(lambda x:x/300, viewers_number))
nx.draw_networkx_nodes(Gcc, pos, ax=ax0, node_size=scaled_viewers_number)
ax0.set_title("Connected components of G")
ax0.set_axis_off()
ax1 = fig.add_subplot(axgrid[3:, :2])
ax1.plot(degree_sequence, "b-", marker="o")
ax1.set_title("Degree Rank Plot")
ax1.set_ylabel("Degree")
ax1.set_xlabel("Rank")
ax2 = fig.add_subplot(axgrid[3:, 2:])
ax2.hist(degree_sequence, bins=100)
ax2.set_title("Degree histogram")
ax2.set_xlabel("Degree")
ax2.set_ylabel("# of Nodes")
fig.tight_layout()
plt.show()







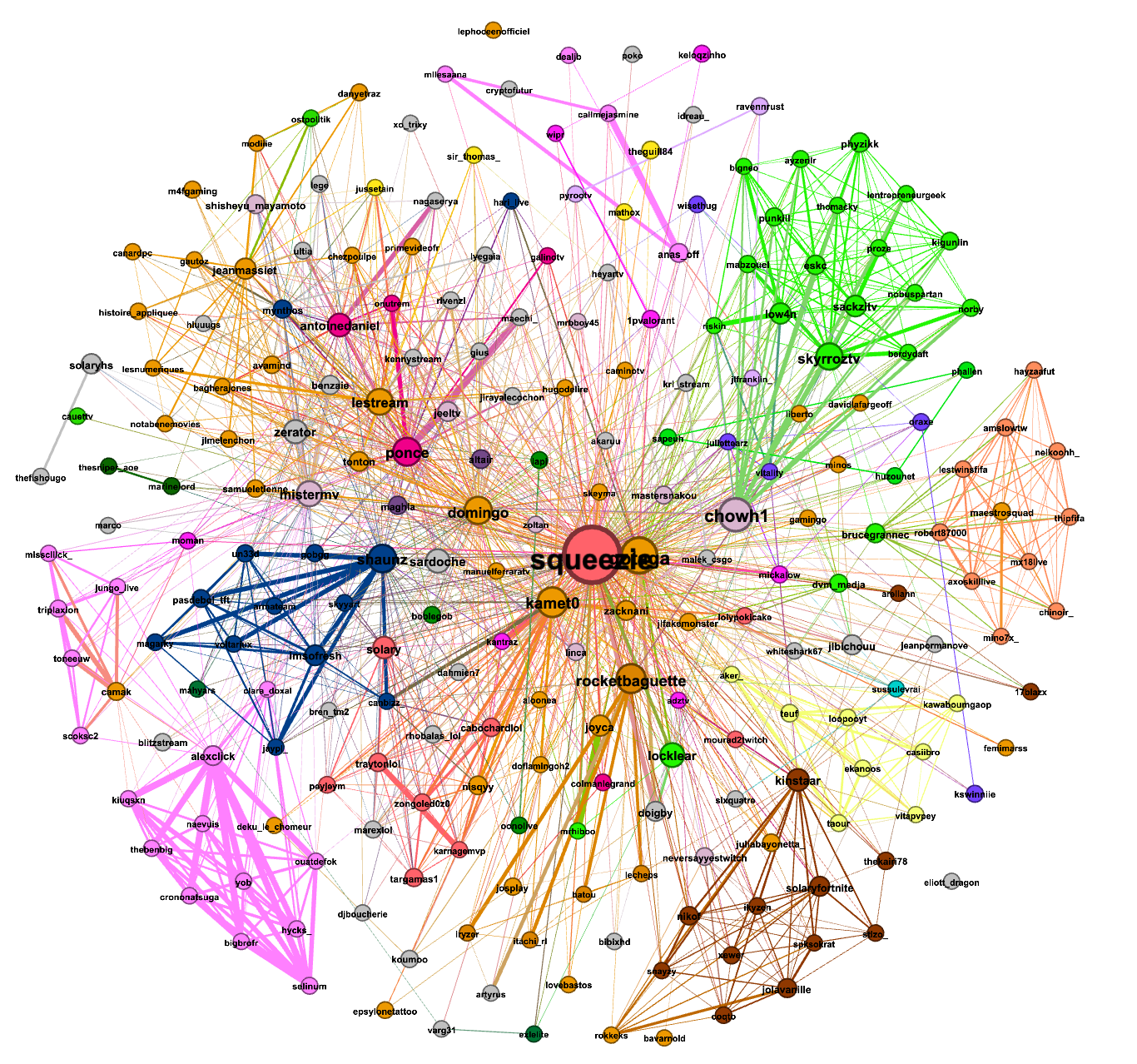

 The first graph was made from the data gathered from (Sunday)12/12/2021-15h37 to 13/12/2021-15h22:
The first graph was made from the data gathered from (Sunday)12/12/2021-15h37 to 13/12/2021-15h22:
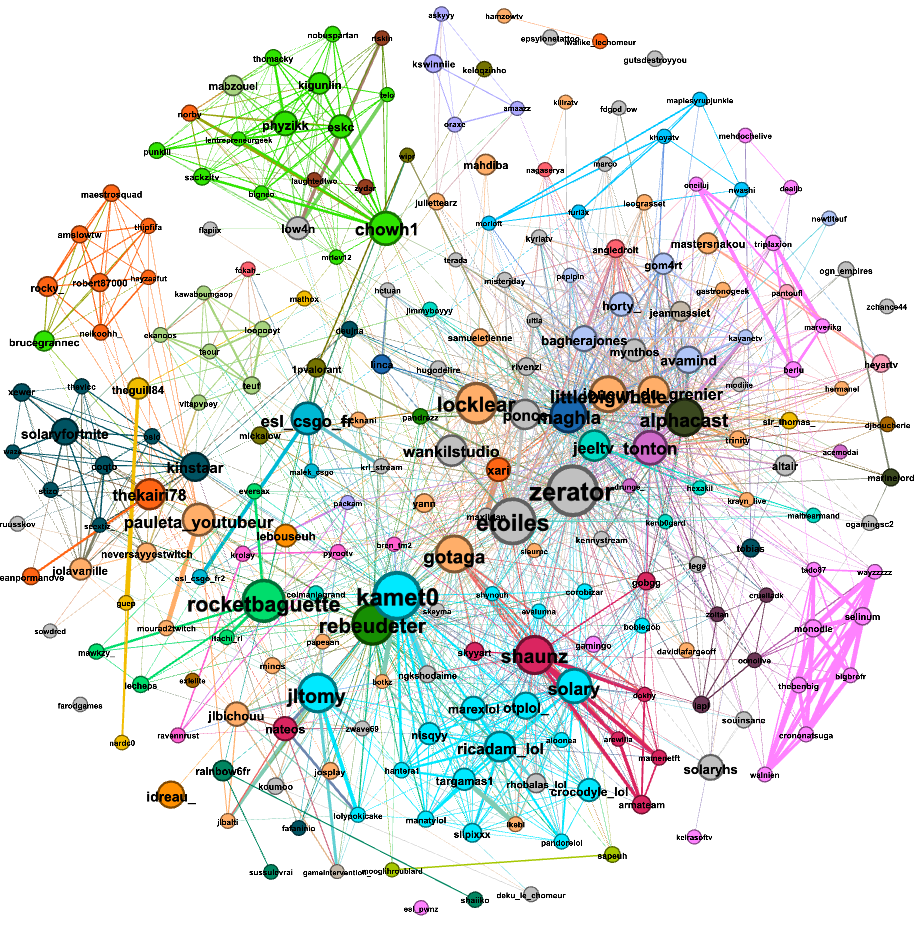 The first graph was made from the data gathered from (Monday)13/12/2021-15h37 to 14/12/2021-15h22:
The first graph was made from the data gathered from (Monday)13/12/2021-15h37 to 14/12/2021-15h22:
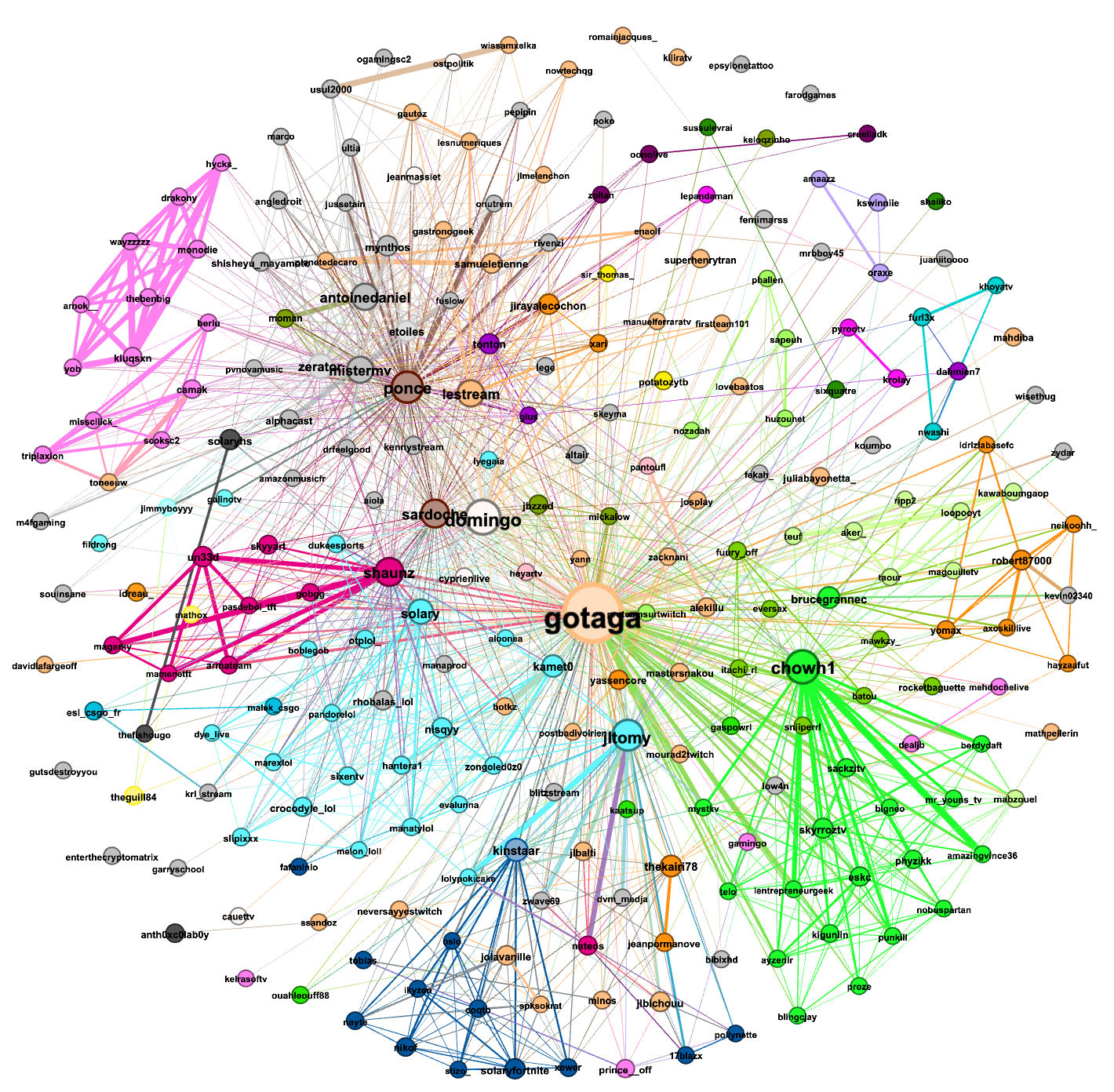 The first graph was made from the data gathered from (Tuesday)14/12/2021-15h37 to 15/12/2021-15h22:
The first graph was made from the data gathered from (Tuesday)14/12/2021-15h37 to 15/12/2021-15h22:




